Clustering Windows Server2008
I am delivering a webcast on High Availability with virtual machines as part of the Virtualization webcast series. It is a good overview of server clustering for Windows Server 2008 and an introduction to using a virtual machine as a clustered resource. The material is excellent! I have recorded some demonstrations to go with the content. I will put it in 2 parts because it is somewhat lengthy. Enjoy! and I'll watch for you on the live webcast.
One of the concerns with running multiple virtual machines on one physical server is that if the server goes offline, either through planned or unplanned downtime, all of the virtual machines hosted on the virtualization host will also be offline. This can magnify the effects of a simple server reboot.
Windows Server 2008 and Hyper-V provide a solution to this. Windows Server 2008 provides failover clustering, which enables you to host applications and services on one server, with automatic failover to another server if the host server is unavailable. This feature was available in Windows Server 2003, but has been significantly enhanced in Windows Server 2008. One of the applications that you can run on a failover cluster is a Hyper-V virtual machine. By using these tools, you can avoid virtual machine downtime, even when you have to shut down a host computer.
A cluster is a group of computers working together to run a common set of applications and to present a single logical system to the client and application. The computers in the cluster are physically connected by local-area network (LAN) or wide-area network (WAN) and programmatically connected by cluster software. These connections allow workloads to fail over to another computer in the cluster in the case of network failure of scheduled maintenance, for example.
In a failover cluster, each node in the cluster: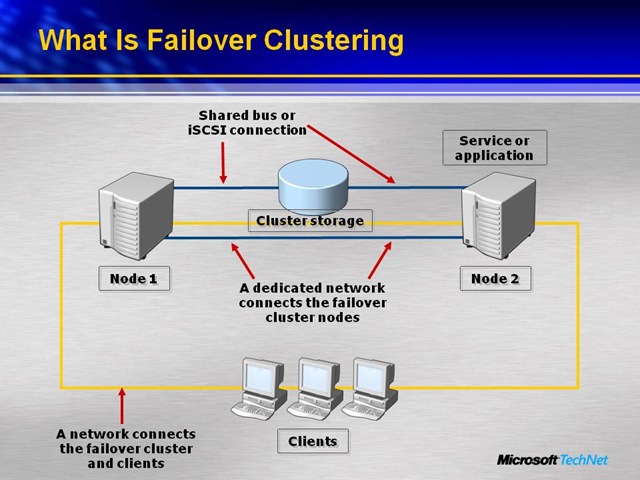
•Has full connectivity and communication with the other nodes in the cluster.
•Is connected to a network through which client computers can access the cluster.
•Is connected through a shared bus or Internet Small Computer System Interface (iSCSI) connection to shared storage.
•Is aware of the services or applications that are running locally and the resources that are running on all other cluster nodes.
Most clustered applications, and their associated resources, are assigned to one cluster node at a time. The node that has access to those cluster resources is the active node. If the nodes detect the failure of the active node for a clustered application or if the active node is taken offline for maintenance, the clustered application is started on another cluster node. To minimize the impact of the failure, client requests are immediately and transparently redirected to the new cluster node.
Clustered services that contain an IP address resource and a network name resource (as well as other resources) are published to clients on the network under a unique server name. Because these groups appear as individual logical servers to clients, they are called a cluster instance.
Users access applications or services on an instance in the same way they would if the application or service were on a non-clustered server. Usually, the application or user does not know that they are connecting to a cluster, nor to which node they are connected.
 Resources are physical or logical entities, such as a file share, disk, or IP address, that the failover cluster manages. Resources may provide a service to clients or be an integral part of the cluster. Resources are the most basic and smallest configurable unit. At any given time, a resource can run only on a single node in a cluster, and is online on a node when it is providing its service on that specific node.
Resources are physical or logical entities, such as a file share, disk, or IP address, that the failover cluster manages. Resources may provide a service to clients or be an integral part of the cluster. Resources are the most basic and smallest configurable unit. At any given time, a resource can run only on a single node in a cluster, and is online on a node when it is providing its service on that specific node.
A failover attempt consists of the following steps:
1. The cluster service takes all the resources in the instance offline in an order that is determined by the instance’s dependency hierarchy: dependent resources first, followed by the resources on which they depend. For example, if an application depends on a physical disk resource, the cluster service takes the application offline first, which allows the application to write changes to the disk before the disk is taken offline.
2. When all the resources are offline, the cluster service attempts to transfer the instance to the node that is listed next on the instance’s list of preferred owners.
3. If the cluster service successfully moves the instance to another node, it attempts to bring all the resources online; this time it starts at the bottom of the dependency hierarchy. Failover is complete when all of the resources are online on the new node.
4. When the node becomes active again, the cluster service can fail back the instances that were originally hosted by the node. When the cluster service fails back an instance, it uses the same procedures that it performs during failover; that is, the cluster service takes all the resources in the instance offline, moves the instance, and then brings all the resources in the instance online.
One of the most significant changes in failover clustering in Windows Server 2008 is the concept of quorum. In previous versions of Windows clustering, you only had one option for configuring quorum, in Windows Server 2008, you have three new options.
The failover cluster quorum configuration determines the number of failed nodes or failed storage and network components that the cluster can sustain while continuing to function. Quorum prevents two sets of nodes from operating simultaneously as the failover cluster. Simultaneous operation could happen when network problems prevent one set of nodes from communicating with another set of nodes. Without a quorum mechanism, each set of nodes could continue to operate as a failover cluster, resulting in a partition within the cluster. 
To prevent problems caused by a split in the cluster, failover clusters use a voting algorithm to determine whether the cluster has enough votes to maintain quorum. Because a given cluster has a specific set of nodes and a specific quorum configuration, the cluster will know how many votes are required. If the number of votes drops below the majority, the cluster stops running. Nodes will still listen for the presence of other nodes, in case another node appears again on the network, but the nodes will not function as a cluster until a consensus is reached.
See the following link for more information
Windows Server 2008: Failover Clustering
https://www.microsoft.com/Windowsserver2008/en/us/clustering-home.aspx