Announcing Extended Word breaking capabilities for Search in SharePoint Online
In an endeavor to improve the SharePoint Online search experience, engineering has released two new managed property settings: Language Neutral Tokenization and Finer Query Tokenization. These are available as two checkboxes when you create any new managed property, or when you edit a custom managed property. You won’t see these checkboxes when you edit any of the managed properties that come with SharePoint by default.
What is tokenization
Tokenization is the process of breaking a stream of text up into words, phrases, symbols, or other meaningful elements called tokens. The token is the smallest element of information one can search for. Tokenization is useful both in linguistics (where it is a form of text segmentation), and to handle specific entities like email addresses, phone numbers, and URLs. A basic strategy for tokenization is to break words on white spaces and replace non-alphanumerical characters, such as punctuation marks, with white space. Breaking on white spaces works fine for a language like English, but not so well for East Asian languages, which don’t use spaces between words. In some languages, removing diacritics changes the meaning of the word. Therefore, search tokenizes according to the language it detects in the content. In certain situations, language dependent tokenization results in fewer matches for a query.
When a search query is processed, the query is fragmented that is broken into smaller parts. SharePoint search by default breaks the indexed content into smaller parts than it does with queries. As of today, if a query contains alphanumerical characters, the coarser tokenization of queries might result in search not finding a match for the query.
Search discovers information by crawling items on your site. The discovered content and metadata are called the properties of the item. The search schema has a list of crawled properties that helps the crawler decide what content and metadata to extract.
Let us look at what these properties are expected to do .
Language Neutral Tokenization: If you have multilingual content and the managed property contains tags that are based on metadata term sets or other identifiers, using language neutral tokenization for the content of the managed property helps finding a match for the query. Search depends on language when it breaks queries and content into parts (tokenization).
For example, there are few documents in a library that has contents in both English and Chinese. You decide to assign a unique identifier to each of these documents and create a column called “MyDocLibID” and assign a identifier that contains non-alphanumerical characters, such as “ID#161516”. A crawl property will be created automatically. You create a new managed property and map the two to each other, so users can search the “Document identifier” column by querying against the column’s managed property.
Query experience will vary if you decide to keep the default tokenization or if you choose to turn on the Language Neutral Tokenization on the “MyDocLibID” managed property. This is because the identifiers would be tokenized differently based on if the property is enabled or not. If the languages are different, search might not find a match for the query. Turn on language neutral tokenization for the “MyDocLibID” managed property so all identifiers are tokenized the same way. The query is browser locale independent and users would be able to query for MyDocLibID: ID#161516 and lookup the document.
Finer Query Tokenization: Consider turning on finer query tokenization for a custom managed property if it contains separators such as dots and dashes. Search tokenizes queries coarser than content. If a managed property "ID" contains the string "1-23-456#7", and you query ID:"1-23", you might not get a partial match because search didn't break the query into small enough parts. By default, search returns partial matches between queries against a managed property and its content. If you want to do a partial match, like “1-23-456”, search might not find a match because queries are tokenized more coarsely than content. If you turn on finer tokenization, it’s more probable that search finds a match for the queries. Consider selecting finer query tokenization if the content of this managed property contains separators such as dots and dashes.
Configuration Guidelines
Configuration for search schema can be performed either at single site collection level or at tenant level. Any changes you make on a site collection, only apply to that site collection. There is not a preference on one over the other, however personally I would prefer to turn it on a site collection level since a managed property would ideally be specific to the site. You need to do a re-crawl before the property mapping would work.
Tenant Level Search Schema Configuration
- Browse to a Document library within a SharePoint site and create a column from within the document library settings. Choose single line text as the column type. Name the column as
- Upload a document of different language and add a value to MyDocLibID column example ID#161516.

- Browse to SharePoint admin center with a Global administrator or a SharePoint administrator account.
- Click on Search from the left navigation.
- Within Search Administration, click on Manage Search Schema.
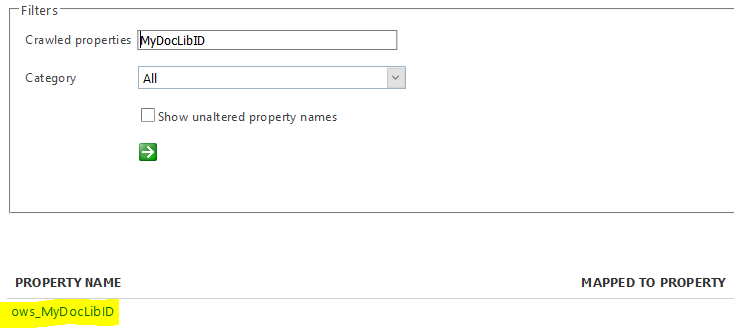
- Click on Crawled Properties .

- Search automatically creates crawled properties for the columns that has been created. Example if you have created a column in your document library called MyDocLibID, you can search for the same in the list of Crawled Properties. It should return the property name as ows_MyDocLIbID. At this stage the property is not mapped to any managed property .
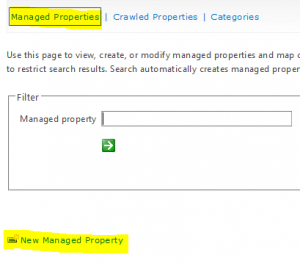
- Next you need to create a managed property and map the crawl property. Click on Managed Properties and click New Managed Property.
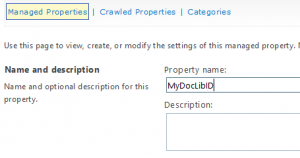
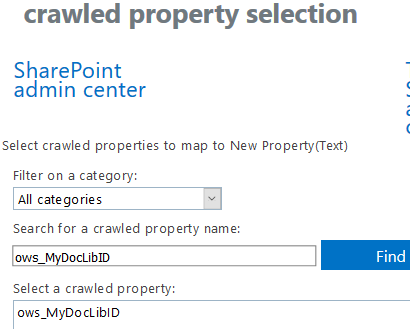
- In this example, our focus will be only in the two new properties, as rest of property functionality remains the same as of today. Type in a name of the managed property example “MyDocLibID”.
-
- I have made the property Queryable, Retrievable, Safe (as I want to test anonymous user query functionality), Token Normalization.The key properties for this functionality to work is Language Neutral Tokenization, & Finer Query Tokenization. Select the check boxes next to these properties.
-

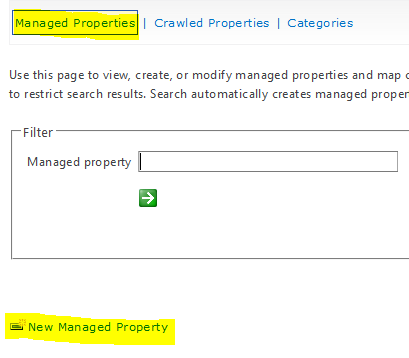
- Map the managed property to crawl property that was created for the document library, in this case ows_MyDocLIbID. Within Mappings to crawled properties section click on Add a Mapping.

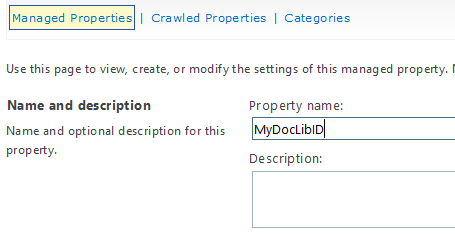


15.From within Crawl property selection search for ows_MyDocLibID and from within the result select the same and click on OK to add the mapping.
16.This completes the configuration. Run a recrawl for all site collection that you want to leverage the property mapping you made.
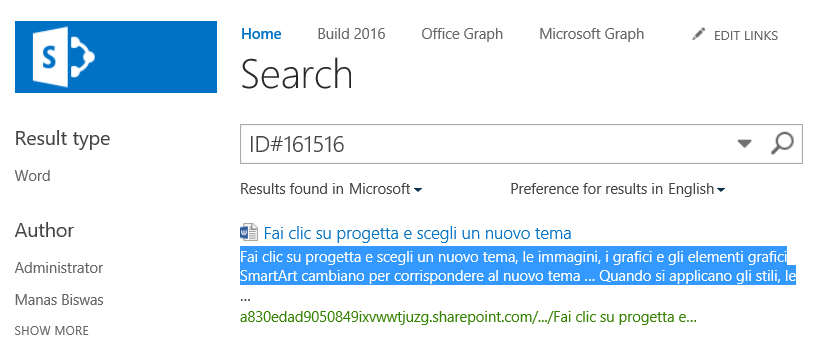
17. Navigate to a search center and lookup a document that has the associate id. Example https://<tenanturl>.sharepoint.com/_layouts/15/osssearchresults.aspx?u=https%3A%2F%2Ftenanturl%2Esharepoint%2Ecom&k=ID%23161516.
Search schema can be changed for a specific site collection or the whole tenant. A change on a site collection level schema applies only to that site collection whereas the tenant level schema change applies to all site collections across the tenant. We have already discussed about tenant level schema change, let us now look at a site collection level schema change.
Site Collection Level Search Schema Configuration
- Browse to your site with a site collection administrator.
- Click Settings, and then click Site settings.
- Under Site Collection Administration, click Search Schema.
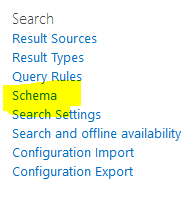
- In the Property Name column on the Managed Properties tab, in the Filter box type the Name of the Managed Property

- Optionally you can create a new one by clicking on the New Managed Property tab.
- New Managed property creation steps at site collection level are identical to the ones we discussed above for tenant level. Follow the steps below if you are editing an existing custom managed property. From search results in step 4 above click on the managed property, and select Edit/Map property.
- Scroll down to the new settings on the Edit Managed Property page, check the two new managed properties (Language Neutral Tokenization, Finer Query Tokenization) to turn on the new capabilities and then click OK.

- Now if you look up documents associated with this manage property, you will be able to leverage the enhanced Wordbreaking features mentioned above.


Search schema controls what users can search for and how you can present the results to your end users. The two new properties Language Neutral Tokenization and Finer Query Tokenization would enhance the end user experience while looking up multilingual, special character titled documents, in a much more streamlined manner.