Storage Spaces Data Deduplication
While demonstrating some of the features of Storage Spaces during the OEM Server Roadshow, one of the pieces of that technology which gets some attention is the data de-duplication capabilities, so I thought it was time I did a post focusing on that and providing some resources for more information. To start with, Storage Spaces is a storage virtualisation feature inside of Windows Server 2012 and Windows Server 2012 R2, that allows you to pool commodity disks into pools and create virtual disks from this storage. These disks can have other technologies enabled, such as Tiered Storage, where SSD storage can accelerate the disk performance, thin provisioning, and the topic for today, deduplication.
Being a new feature to Windows Server 2012, you will find you need to access it via Server Manager, or alternatively you can use PowerShell to manage it. However, before accessing it, you need to enable it via the Add Roles And Features Wizard, PowerShell or DISM.
Once enabled, you can open Server Manager and navigate to File And Storage Services on the left hand pane.
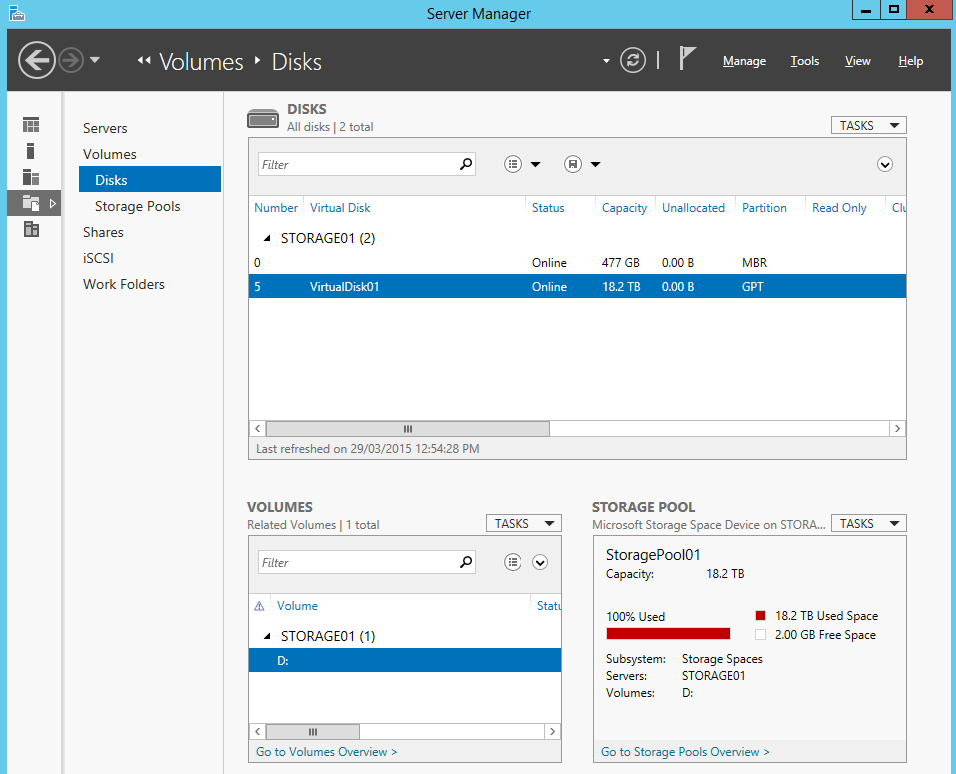
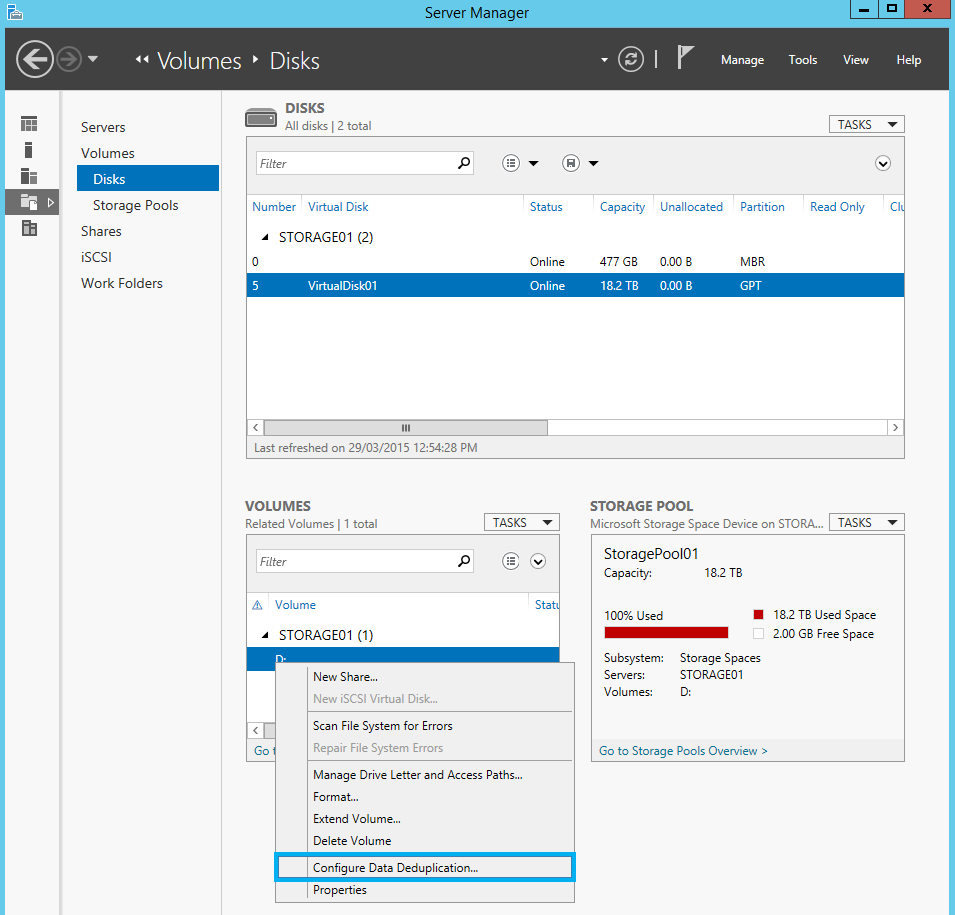
From there you enable Deduplication on a volume by volume basis. This gives the flexibility to have volumes that don't have deduplication applied, such as where you would store non-VDI related virtual machines, for example, or for data that doesn't benefit from compression at all.
There are two main scenarios where you can use deduplication today, these are for Virtual Desktop Infrastructure (VDI) deployment, and for general purpose file servers. The VDI scenario involves running desktop virtual machines based on a client OS such as Windows XP or Windows 8.x, but the important thing to note is that you shouldn't be running this on your Hyper-V server, this should be a separate dedicated storage device. The reason for this is that first of all, your Hyper-V server should only be running as your Hyper-V server, and secondly, the CPU demands of data deduplication will be kept away from the Hyper-V server as well.
in this scenario your open VHD or VHDX files can be deduplicated, and you can improve the reads and writes of files. The amount of data saved will depend on your scenario, but you could see savings in the 90-95% range. While this number may sound unusually large, once you think about the amount of duplicate information across the multiple VHD or VHDX files you get an understanding of how these numbers are achieved. In the image below, you will see that the default file extensions to include are related to Hyper-V workloads, but that the VHD and VHDX files are not excluded as that is where the majority of the savings will come from.
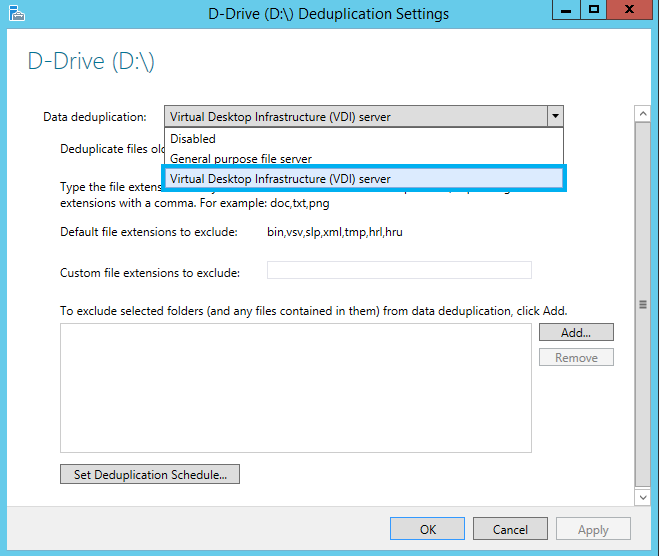
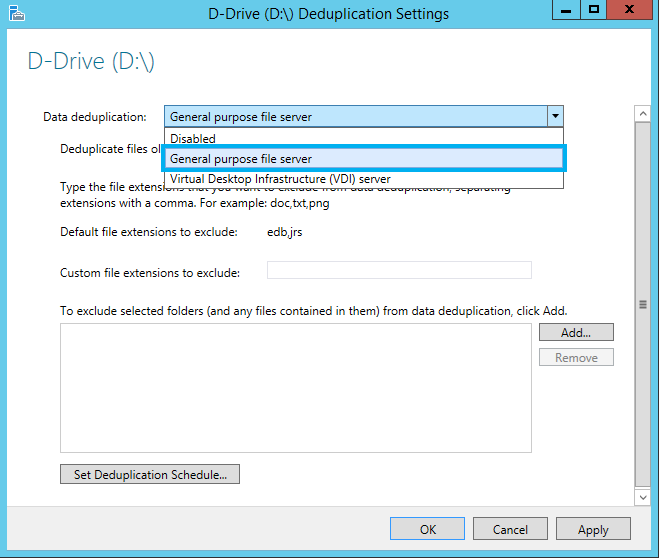
The second scenario is for a general purpose file server. It's important to note that you can't run data deduplication on boot or system volumes, only on data volumes, and the compression rates will depend on the type of data that is saved to that server. You should still see significant storage savings here. Note that Exchange databases are excluded from deduplication by default.
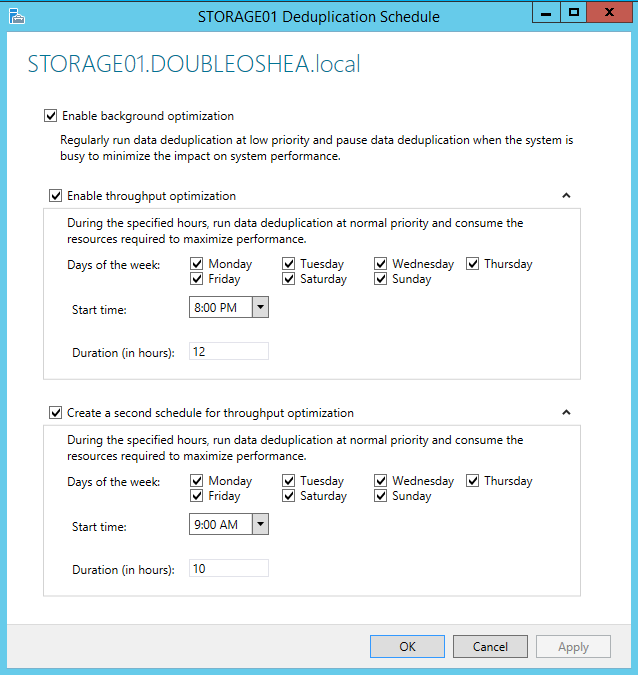
When enabling Deduplication, you need to set a schedule, and you can see below that you can set two different time periods, such as the weekdays and weekends, and you can also enable background optimisation to run during quieter periods.