Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Ask The Performance Team
URL
Copy
Options
Author
invalid author
Searching
# of articles
Labels
Clear
Clear selected
application compatibility
applications and services
Architecture
base video
com dcom
debugging
Default apps
Display
dst
dump
dxdiag
File associations
fonts
General
gpo
graphics
hang
Internet Explorer
jobs microsoft
leak
memory
memory management
Networking
Pages
Performance
PowerShell
printbrm
print fixit
Printing
print migration
RDS
Remote Desktop Services
remote desktop services deployment
remote desktop services installation
Search
Security
server core
server hung
server manager
shell
support center
Surveys
task scheduler
team bios
Terminal Server
Troubleshooting
two minute drill
two minute drill print migration
Virtualization
WillAftring
Windows 10
Windows 7
windows 8
windows installer
windows server 2003
windows server 2008
windows server 2008 r2
windows server 2012
windows vista
windows xp
wmi
wmi scripting
wmiseries
- Home
- Windows Server
- Ask The Performance Team
Options
- Mark all as New
- Mark all as Read
- Pin this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed
15.3K
12.9K

20.4K






11.2K

12.6K
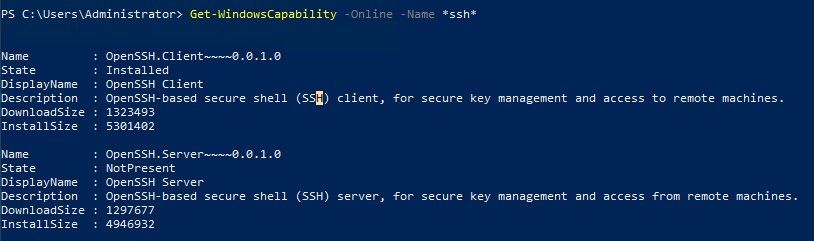


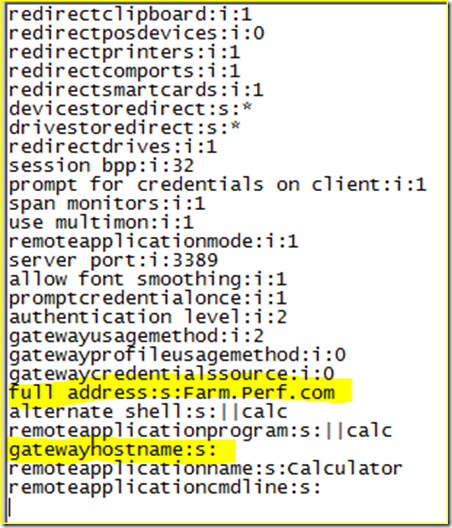
18.7K
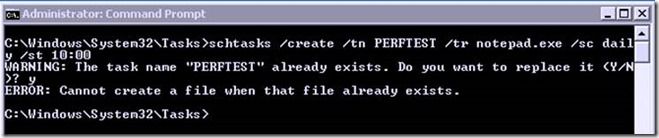
19.2K
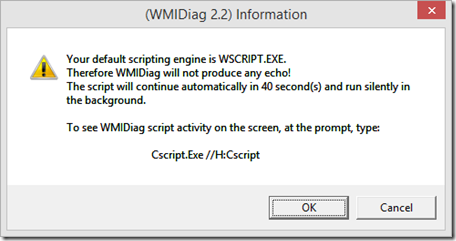
28K
40.8K

Latest Comments