Hard Disk Failure Error Messages in AD Replication?
Hi everyone, David Beach here today.
Here’s a fun AD Replication error from Windows Server 2003:
Sitename\DCName via RPC
DC object GUID: abc12345-6789-0123-4567-890abcdefabc
Last attempt @ 2011-03-15 12:15:15 failed, result 1127 (0x467):
While accessing the hard disk, a disk operation failed even after retries.
8 consecutive failure(s).
Last success @ (never).
If you’ve seen that in a repadmin.exe output, your first reaction was probably along the lines of: “Wait, what?” Especially when it only happens for one partition.
It turns out that this error code doesn’t really mean what it appears to mean. What’s happening here is that the JET database engine is returning an error code to Active Directory like -1206 (JET_errDatabaseCorrupted). AD then tries to map that Jet error to a Win32 error code, and the result is what you see above.
Note: To find out what the underlying JET error code means use NTDS diagnostic logging which you can turn on via the registry. Be very careful if you do this – it will flood your event logs, and you may find yourself in a needle-in-a-haystack situation trying to parse useful data out of them afterwards. If you’ve ever wondered what all the different JET error codes mean, you can look here.
Fixing this error is a very easy process, but your change control folks may hate you for it in the end:
First, find the DC that’s the source of all the problems. To do this, I recommend running repadmin /showrepl * /csv >somefile.csv – look and see who everyone else is having trouble replicating FROM with the error above (remember, AD replication connections are always pull operations, so when you look at repadmin output on a server, what you’re seeing is the status of the last attempted pull). That’s your bad DC.
The /CSV above goes and gets this kind of data for every DC that it can contact and then dumps it in a format you can import into Excel to manipulate (this makes it much easier to compare between DCs). For blog readability, here’s a screenshot of what one DC looks like in .txt format:
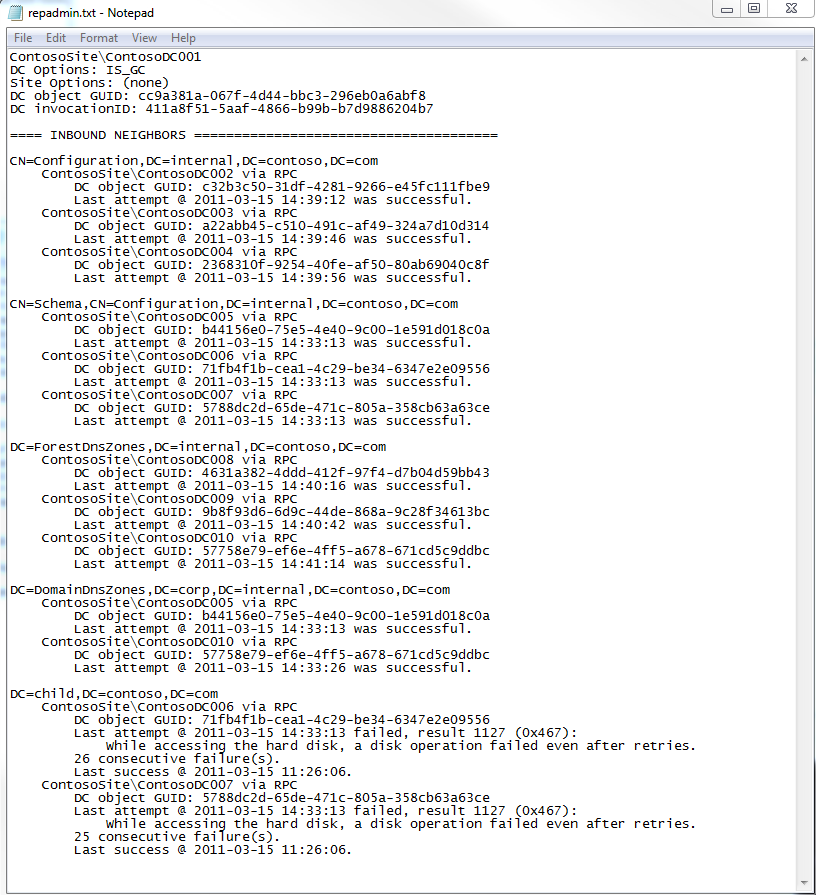
You can see from the above that this DC is complaining about the problems with one partition in the database, which is usually how this failure will come up.
Once you’ve found the DC that’s causing all the problems (it will usually be one domain controller that everyone is having trouble replicating from), then you can take some steps to try and recover the database. I should mention here that in the vast majority of these cases we’ve seen, the database was unrecoverable and the DC had to be demoted. Here’s what to do:
1. Boot to Directory Services Restore Mode using F8.
2. Run ntdsutil and type “files integrity” at the main prompt.
This will execute an integrity check on the database files. It will very likely come back and tell you that errors were found (if it doesn’t, make sure you have the right DC).
3. If the integrity check found errors, execute a semantic database analysis. To do that, at the main ntdsutil prompt, type “semantic database analysis”. Then, at the next prompt, type “Go”
When you do this, ntdsutil does a low-level formatting check on the structure of the database. It looks for structural problems that can cause queries to fail. This will take a short time depending on the size of your database, and then will tell you what it found.
4. To tell the semantic checker to try and fix things that it found, run it again, but this time type “Go Fixup”. This will execute the checker again in Fixup mode, meaning that it will try to correct errors as it encounters them. This is what we call a safe repair – it won’t delete data, and if it encounters a record that it can’t reconstruct properly, it will skip that record and move on to the next rather than damage the database further.
When the check above finishes, ntdsutil will try to tell you if there are any errors remaining in the database. As mentioned above, in most of these cases, the database was too far gone to be recovered, so we saw errors even after the semantic checker was done (or in some cases it was forced to abort). You can reboot to normal mode if you want to see how things perform. At this point you should get a current backup of the DC with systemstate and all files, as the next steps may cause you to lose data and your forensic trail. You can also trying restoring an older systemstate backup from before the failure.
If replication is still failing with the same error, then you only have one option left to you – demote the domain controller. To do this, use dcpromo /forceremoval. The /forceremoval option tells dcpromo to ignore errors and proceed with demotion. This is necessary because in order to demote gracefully, a domain controller has to do one final replication cycle with its peers. Since replication is irrevocably broken in this case, you’ll need to override that to proceed.
The dcpromo process will locally remove the information in AD and DNS that designates this machine as a domain controller, but make sure you run through this metadata cleanup article afterwards on a surviving DC; the other domain controllers won’t know this server has been demoted. Once this is done, your former domain controller will now be a member server, and you can take whatever recovery steps seem appropriate. We usually recommend formatting the hard drive and reinstalling the OS, as well as making sure drivers, bios, and firmware are all updated before you promote the machine to be a domain controller again.
Regardless of whether you end up rebuilding your DC or not, you want to think about root cause here. Most of the time, JET database corruption happens because of a hardware issue – a flaky hard disk controller, a bad memory chip, or even just a hard drive that decides to drop some sectors suddenly. It can also happen because of problems with installed third-party file system filter drivers. The bottom line is that if you see this happen to a server, you want to make sure there’s not another issue happening under the hood before you go and make it a DC again, so get whatever tools your hardware vendor provides to check it out and make sure it’s all in good shape.
This might be a good time to mention that you should have multiple DCs so that your enterprise has some resilience if you encounter this kind of unexpected failure. You do have multiple DCs in each domain you’re running, right?
--David “there’s only one way to be sure” Beach