クラスターディスク ClusDisk.sys の Persistent Reservation について
いつも弊社製品をご利用いただきまして誠にありがとうございます。
Windows プラットフォーム サポートの石田です。
今回は、Microsoft Windows Server Failover Cluster の共有ディスクに対する予約 (Persistent Reservation) の
動作についてご紹介させていただきます。
クラスターサービスでは共有ディスクの排他制御を行うため、SCSI-3 で規格されている
Persistent Reserve コマンドセットを利用しています。
そのため、利用する HBA と共有ディスクを提供するストレージは SCSI-3 に対応している必要がございます。

クラスターで利用される共有ディスクにアクセスする際、ディスク毎に管理されている Reservation Table に
ノード毎に一意に識別できる予約キーを登録します。
最初にキーを登録できたノードがディスクをオンラインにします。
既に別のノードによってキーが登録されておりキーの登録に失敗した場合は、キーが解放されるまで待機状態となります。
ディスクをオンラインにしているノードはディスクに対して 3 秒ごとに Persistent Reserve コマンドを
発行して予約情報を更新します。
ノード 1 とノード 2 にてディスクへ予約キーが登録されるまでの流れ、および障害が検知された際の動作については
以下のようになります。
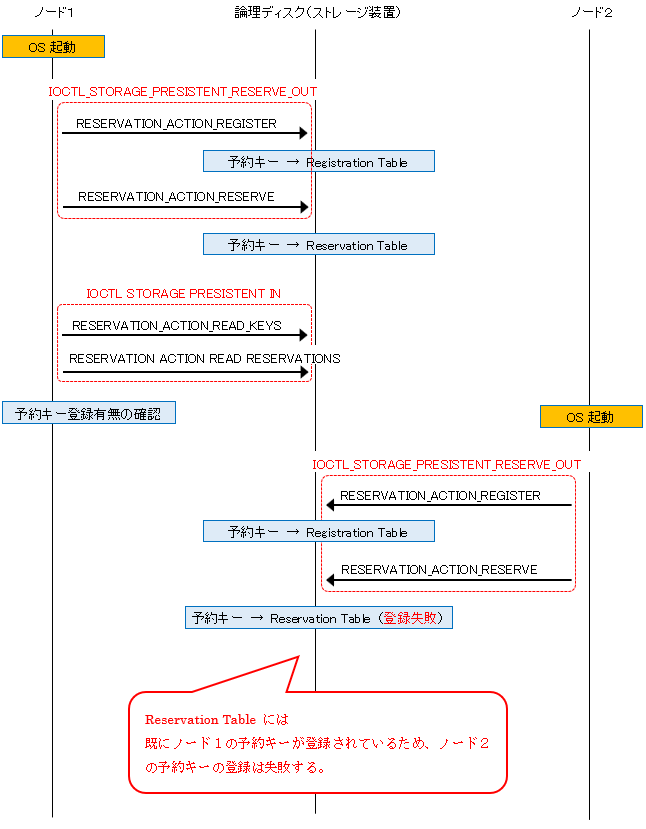
1. ノード 1 のクラスター起動時に対象のストレージに向けて Register & Reserve を発行しストレージの
Registration TableおよびReservation Tableに予約キーを登録します。
2. ノード 1 では続けて予約キーが登録されているかどうか確認します。
3. ノード 2 のクラスター起動時に対象のストレージに向けて Register & Reserve を発行し予約キーの登録を試みます。
ただし、Reservation Table へのキーの登録は既にノード 1 のキーが登録されているため失敗します。
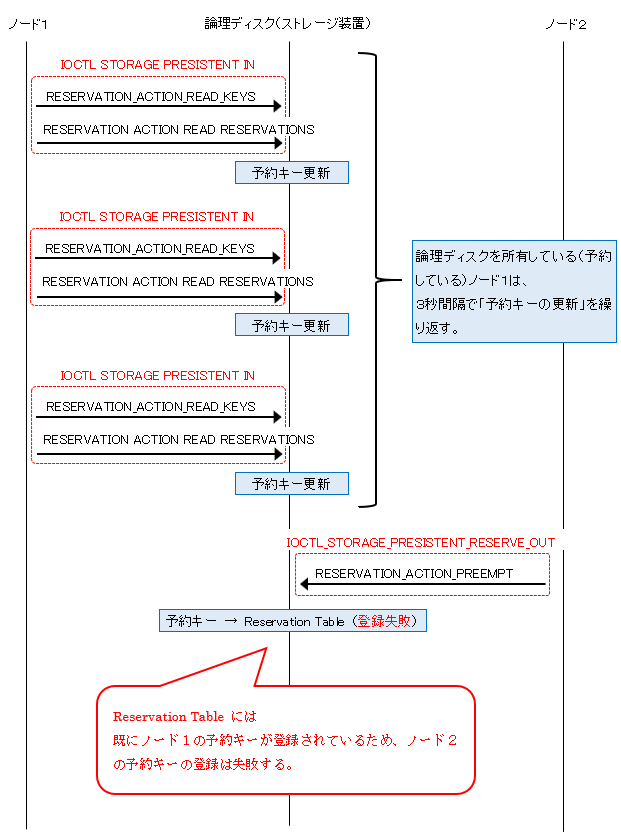
4. ノード 1 にて 3 秒間隔で対象のストレージに向けて Read コマンドを発行し、予約キーの更新を行います。
5. ノード 2 にて対象のストレージに向けて Preempt コマンドを発行し、再度、予約キーの登録を試みます。
ただし、ノード 1 にて予約キーが更新されているため、失敗します。
また、ノード 1 では継続して対象のストレージに向けて Read コマンドを発行し、予約キーの更新を行います。
ノード 2 はクラスターの正常性が変化するまで待機します。
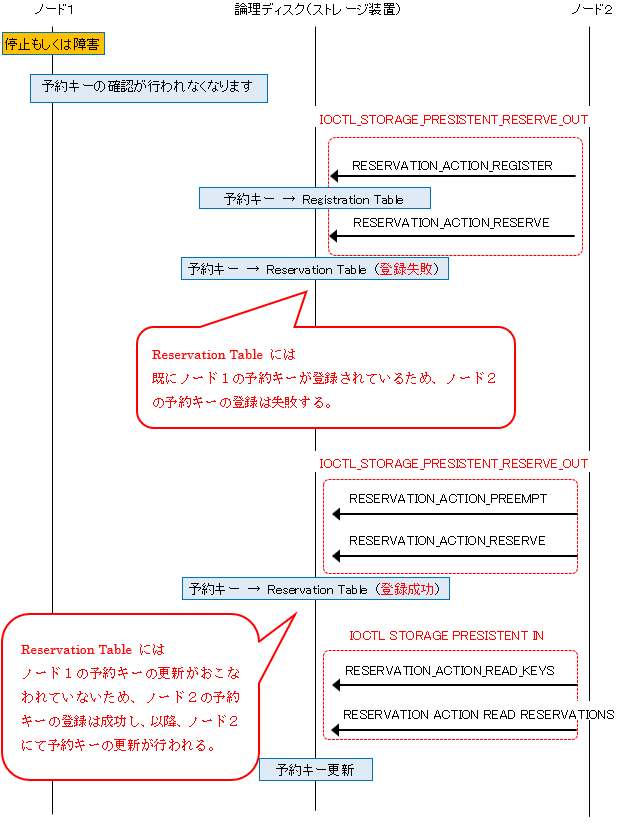
6. ノード 1 にてハングアップやシステム停止などが発生すると、予約キーの更新が行われなくなります。
7. クラスター ディスク リソースのフェール オーバーが発生するとノード 2 にて対象のストレージに向けて
Register & Reserveを発行し予約キーの登録を試みます。ただし、Reservation Table へのキーの登録は
既にノード 1 のキーが登録されているため失敗します。
8. ノード 2 にて対象のストレージに向けて Preempt コマンドが発行され、再度、予約キーの登録を試みます。
この際、ノード 1 にて予約キーの更新は行われていないため、成功します。
9. ノード 2 にて 3 秒間隔で対象のストレージに向けて Read コマンドを発行し、予約キーの更新を行います。
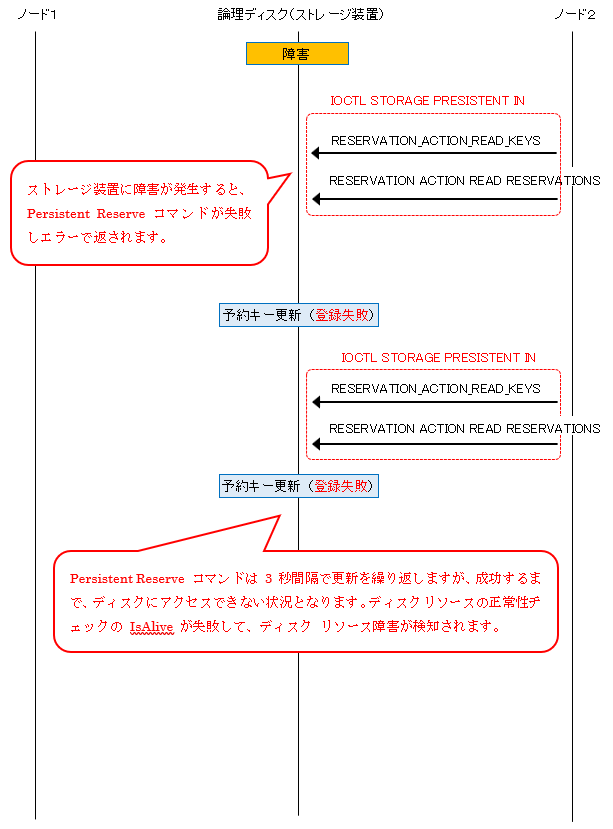
10. ストレージ 装置に障害が発生すると、ノード2から発行されているPersistent Reserveコマンドが失敗します。
11. Persistent Reserveコマンドが失敗すると、ノード 2 のディスク リソースの正常性チェック (IsAlive) が
失敗しディスク リソースの障害が検知されます。
以上となります。
本情報の内容(添付文書、リンク先などを含む)は、作成日時点でのものであり、予告なく変更される場合があります。