Hyper-V クラスター環境にて、クラスター対応更新 (CAU) のライブ マイグレーションがメモリ不足で失敗する
こんにちは。Windows プラットフォーム サポートの加藤です。
本日は、Hyper-V クラスター環境で、クラスター対応更新 (CAU) の実行中にライブ マイグレーションがメモリ不足で失敗し、クラスター対応更新が停止する事象についてご案内いたします。
クラスター対応更新では、更新プログラムの適用時に、役割のドレイン (他のノードに退避) やノードの再起動、再起動完了後のフェールバックを自動で実施しますが、Hyper-V クラスター環境では、このフェールバックのライブ マイグレーションがメモリ不足で失敗する場合がございます。
これは、クラスター対応更新の実施時に、ドレインとフェールバックのライブ マイグレーションが状況によっては、同時に実施される可能性があるためです。
ドレインでは、移動時に全ノードのメモリの空き容量を確認し、各ノードのメモリ使用率が均等になるように、各仮想マシンの移動先を決定するため、メモリ不足で失敗することはありませんが、フェールバックでは、ノードのメモリの空き容量は考慮せず、必ず元のノードに戻ろうとします。
そのため、フェールバック先のノードのメモリがドレインで移動してきた仮想マシンによって全て使われてしまうと、フェールバックのライブ マイグレーションがメモリ不足で失敗します。
この事象が発生すると、ノードのイベント ログ (System) に以下のログが記録されます。
============
ソース: Microsoft-Windows-Hyper-V-High-Availability
イベント ID: 21502
レベル: エラー
説明:
'仮想マシン <仮想マシン名>' のライブ マイグレーションが失敗しました。
'<仮想マシン名>' の仮想マシン移行操作が移行先 '<ノード名>' で失敗しました。(仮想マシン ID ********-****-****-****-************)
'<仮想マシン名>' は初期化できませんでした。(仮想マシン ID ********-****-****-****-************)
RAM 容量が <メモリサイズ MB> の仮想マシン <仮想マシン名> を起動するために必要なメモリがシステムに不足しています。(仮想マシン ID ********-****-****-****-************)
============
以下に、この事象のシナリオを記載します。
-----------------
1. ノード1が修正プログラムのインストールのために、ノード 1 の仮想マシンを他のノードに退避するためにドレインを開始します。ノード1上の仮想マシンはライブ マイグレーションにて、各ノードに分散されます。
2. ノード1の修正プログラム適用が完了し、再起動も完了すると、各ノードに分散していた仮想マシンは、ライブ マイグレーションにて、ノード1 へフェールバックを開始します。
3. 直後にノード2が修正プログラムのインストールのために、他のノードに退避するためにドレインを開始します。ノード 2 の仮想マシンはライブ マイグレーションにて、各ノードのメモリ使用状況を確認し、分散を開始します。
4. この時、ノード2のライブ マイグレーションのキューにはドレインによってノード 1 に移動する仮想マシンがいます。更にフェールバックでノード1 に移動する仮想マシンもライブ マイグレーションのキューに入ります。
5. ライブ マイグレーションのキューの処理順番は、ライブ マイグレーションが開始された順番とは関係ないため、場合によってはドレインの仮想マシンが先に移動され、フェールバックの仮想マシンは後に回されることがあります。
6. フェールバックは、移動先のメモリの空き容量は考慮せず、必ず元のノードに戻ろうとするため、ドレインで移動した仮想マシンでノード1のメモリが使われてしまうと、フェールバックの仮想マシンがメモリ不足でライブ マイグレーション失敗します。
-----------------
上記の事象は、一般的には、仮想マシンの数に対して、メモリの空き容量に余裕がない場合に発生します。
例えば、10 ノードクラスターの環境で、1 ノードを停止した際に、残りの 9 ノードのメモリをほぼ使い切ってしまう環境です。
上記事象は以下の 2 つの回避策があります。
1. クラスター対応更新でフェールバックを無効にする。
2. 指定時間 WAIT するスクリプトを作成し、クラスター対応更新の PreUpdateScript または PostUpdateScript に登録します。
1. フェールバックの無効化
===================
GUI で CAU を設定すると、フェールバックが有効となるため、フェールバックを無効にするためには、Set-CauClusterRole コマンドで設定する必要があります。
1) Get-CauClusterRole コマンドで現在の CAU の設定が確認できますので、まずは現在の設定を確認します。
2) Set-CauClusterRole のコマンドを 1) で確認した設定と -FailbackMode NoFailback を引数で指定して実行します。
Set-CauClusterRole -FailbackMode NoFailback -<他の設定の引数>
Set-CauClusterRole
/ja-jp/previous-versions/windows/powershell-scripting/hh847234(v=wps.630)
--- 抜粋 ---
-FailbackMode
Specifies the method used to bring drained workloads back to the node, at the end of updating the node. Drained workloads are workloads that were previously running on the node, but were moved to another node.
The acceptable values for this parameter are: NoFailback, Immediate, and Policy. The default value is Immediate.
------
2. クラスター対応更新の PreUpdateScript または PostUpdateScript を使用する。
===================
クラスター対応更新の設定で、フェールバックとドレインの間に WAIT を入れ、時間調整することでドレインとフェールバックの競合を避けます。
具体的には、PowerShell コマンドの Start-Sleep を使用して、指定時間 WAITするスクリプトを作成し、作成したスクリプトを CAU のオプションの PreUpdateScript または PostUpdateScript で設定します。
例:20 分 (1200 秒) WAITする場合
テキストファイルに以下のコマンドを記載し、拡張子 ps1 で保存します。
Start-Sleep -s 1200
作成したスクリプトを全ノードの同じパスに配置して、以下の PreUpdateScript または PostUpdateScript にてパスを指定します。
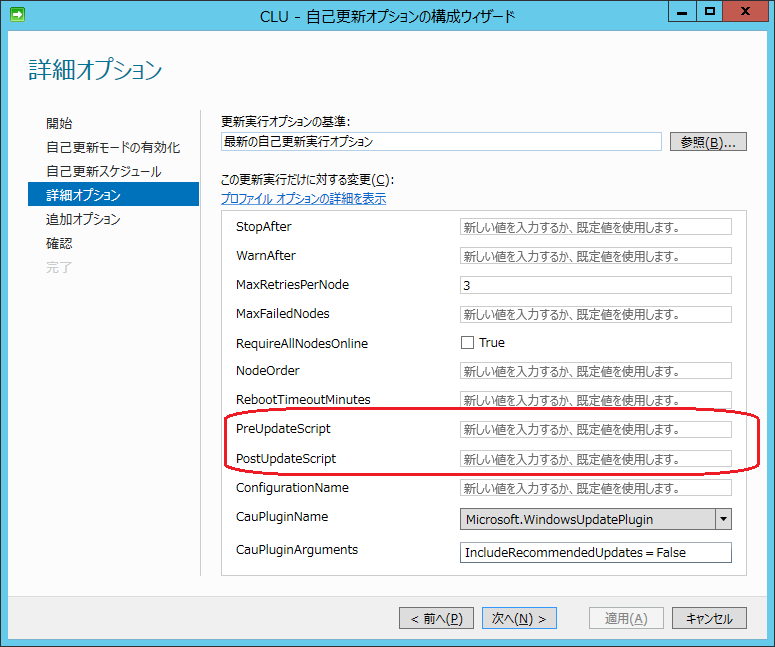
これにより、ノードの再起動完了から次のノードのドレインが開始されるまで、待ち時間を設定することができますので、ドレインとフェールバックのライブ マイグレーションが重なる状況を防げます。
必要なWAIT時間は環境によって異なりますが、ドレイン時に各ノードに 10 台ずつ分散される環境の場合には、10 台のライブ マイグレーションが完了する時間を計測して、その時間の 1.5倍で設定します。
足りない場合には、更に WAIT 時間を延長します。
このブログが皆様のお役に立てれば幸いです。