Longhorn:: 10 Reasons to look at Windows Longhorn Part 7: Failover Clustering
With Windows Longhorn we will change the name of clustering technology. Let's look back at what the cluster terminology was:
When we first introduced the clustering technology in Beta we called it Wolfpack.
In Windows NT 4.0 we called it Microsoft Cluster Service (MSCS) , lot's of people still use this terminology.
With Windows 2000 Server and Windows Server 2003 we called it Server Clustering. Because we introduced a new clustering technology called Windows Compute Cluster server we had to change the name in order to avoid confusion.
Now it will be Windows Server Failover Clustering (WSFC) .
We aim to simplify the cluster installation and management, increase security and stability. Before installing the actual cluster you will have to validate the hardware against a set of tests.
These tests include specific simulations of cluster actions, and fall into the following three categories:
- Node tests: Check if the servers meet specific requirements
- Network tests: Test if the planned server meets the Network requirements like the requirement of two separate subnets.
- Storage tests: Check whether the storage correctly supports the necessary SCSI commands and handles simulated cluster actions correctly.
Once the tests are completed successfully we can start the installation, we have simplified the setup so that the administrators can create the cluster in a few steps, we will also support scripting to automate the installation.
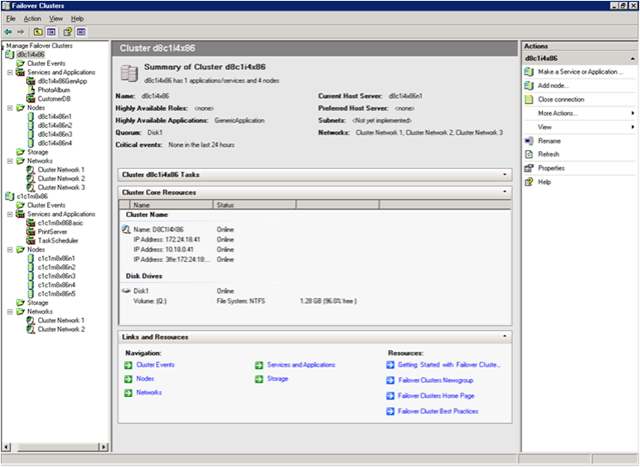
The new management console is based on our MMC technology and let you manage multiple clusters within one central console.
Some other management improvements:
- Use the Volume Shadow Copy Service to capture backups: Full integration with the Volume Shadow Copy Service makes it easier to back up and restore cluster configurations.
- Troubleshoot a cluster: Instead of working with the cluster log, administrators can use Event Tracing for Windows to easily gather, manage, and report information about the sequence of events that occurred on the cluster.
We also made improvements to the cluster infrastructure to maximize the availability:
- Configure a cluster so that the quorum resource is not a single point of failure: For example, in a two-node cluster, an administrator can specify that if the quorum becomes unavailable, the cluster continues running as long as the copies of the cluster configuration database on the two nodes remain available.
Windows Server Failover Clustering will have an improved security model:
- Cluster Service now runs in the context of the LocalSystem built-in account
- No more Cluster Service Account (CSA)
- No more account password management
- No need to pre-stage defined user accounts
We will now have better support for geographically dispersed clusters, the nodes doesn't have to reside onto the same network subnet and we can control the heartbeat timeout, these changes in functionality will let you create clusters without the need of hardware to create V-Lans over WAN network.
Previous Posts in this series:
Part 6: Network Access Protection
Technorati tags: Longhorn, Windows Cluster Server, Microsoft