SQL Server Performance Tuning : Backward Scanning of an Index
One of the key areas to investigate during performance optimization is the indexing strategy. Not building the right index based on the read pattern may be disastrous specially when databases are big. In this article, I will cover a scenario around how SQL Server scans an index while reading BACKWARD, like when ORDER BY Col1 DESC is used in a query.
We shall use the AdventureWorks2012 Database for demonstrating this. I will create a new table TransactionHistory2 for this.
Query1:

I will now add more rows to the table and follow it up by creating a Clustered and a non-Clustered Index on it
Query2:
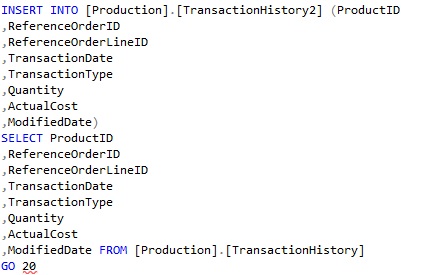
Query3:

As part of the demonstration, I will query for TransactionID,TransactionDate,TransactionType from table TransactionHistory2 by filtering on the attribute TransactionID.
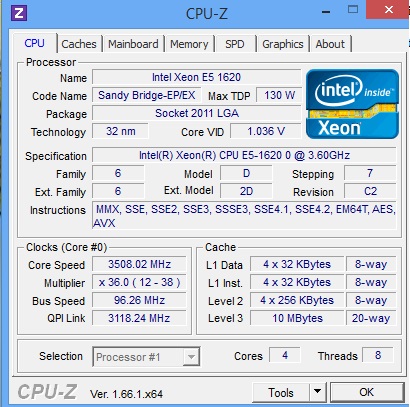
The machine I am using for the demonstration is a 64 bit OS with an Windows 8.1 Enterprise with 16 GB RAM. Also find below the CPU Configuration.
My first goal is to ensure that the queries that I picked up for my demonstration run with parallelism. The property Cost threshold for Parallelism on my SQL Instance is set to 5. I executed the below code changing the value of the predicate TransactionID such that the Estimated Subtree Cost for the query goes over 5. Note that the mentioned properties are of the SELECT operator.
Query4:
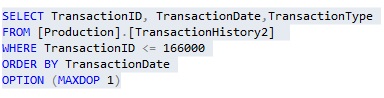

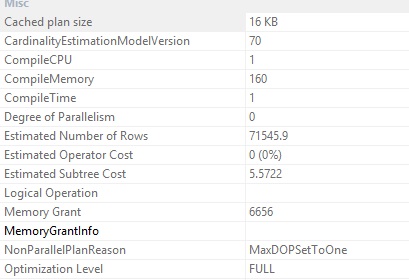
Now, with a value greater than 166000 (I have selected a much higher number) , I go fetch the data ordering first by the TransactionDate in Ascending Order followed by Descending Order.
Query5:


And as expected, SQL Server scans the data in parallel. Lets do the same again but changing the direction of the ordering.
Query6:


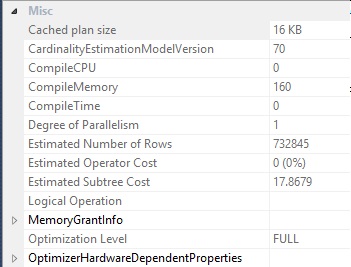
SQL Server now choses a Clustered Scan but does not process the descending order clause with a parallel scan even while the Estimated Subtree Cost is over 17%. That’s because, currently a BACKWARD scan is not possible with parallelism. It is good to be aware of such implications while designing indexes. If the requirement is to fetch data from tables in a descending order, it may be more performant to create an index in descending order. Similarly, if the data needed is ordered by multiple attributes, both in opposite direction of ordering , it will be prudent to store the data within the index in that fashion (column1, column2 desc ) else there will be an explicit sorting of data, which is quite avoidable in such cases.
Thanks for reading!!