Deep Learning Without Labels
Announcing new open source contributions to the Apache Spark community for creating deep, distributed, object detectors – without a single human-generated label
This post is authored by members of the Microsoft ML for Apache Spark Team – Mark Hamilton, Minsoo Thigpen,
Abhiram Eswaran, Ari Green, Courtney Cochrane, Janhavi Suresh Mahajan, Karthik Rajendran, Sudarshan Raghunathan, and Anand Raman.
In today's day and age, if data is the new oil, labelled data is the new gold.
Here at Microsoft, we often spend a lot of our time thinking about "Big Data" issues, because these are the easiest to solve with deep learning. However, we often overlook the much more ubiquitous and difficult problems that have little to no data to train with. In this work we will show how, even without any data, one can create an object detector for almost anything found on the web. This effectively bypasses the costly and resource intensive processes of curating datasets and hiring human labelers, allowing you to jump directly to intelligent models for classification and object detection completely in sillico.
We apply this technique to help monitor and protect the endangered population of snow leopards.
This week at the Spark + AI Summit in Europe, we are excited to share with the community, the following exciting additions to the Microsoft ML for Apache Spark Library that make this workflow easy to replicate at massive scale using Apache Spark and Azure Databricks:
- Bing on Spark: Makes it easier to build applications on Spark using Bing search.
- LIME on Spark: Makes it easier to deeply understand the output of Convolutional Neural Networks (CNN) models trained using SparkML.
- High-performance Spark Serving: Innovations that enable ultra-fast, low latency serving using Spark.
We illustrate how to use these capabilities using the Snow Leopard Conservation use case, where machine learning is a key ingredient towards building powerful image classification models for identifying snow leopards from images.
Use Case – The Challenges of Snow Leopard Conservation
Snow leopards are facing a crisis. Their numbers are dwindling as a result of poaching and mining, yet little is known about how to best protect them. Part of the challenge is that there are only about four thousand to seven thousand individual animals within a potential 1.5 million square kilometer range. In addition, Snow Leopard territory is in some of the most remote, rugged mountain ranges of central Asia, making it near impossible to get there without backpacking equipment.

Figure 1: Our team's second flat tire on the way to snow leopard territory.
To truly understand the snow leopard and what influences its survival rates, we need more data. To this end, we have teamed up with the Snow Leopard Trust to help them gather and understand snow leopard data. "Since visual surveying is not an option, biologists deploy motion-sensing cameras in snow leopard habitats that capture images of snow leopards, prey, livestock, and anything else that moves," explains Rhetick Sengupta, Board President of Snow Leopard Trust. "They then need to sort through the images to find the ones with snow leopards in order to learn more about their populations, behavior, and range." Over the years these cameras have produced over 1 million images. The Trust can use this information to establish new protected areas and improve their community-based conservation efforts.
However, the problem with camera-trap data is that the biologists must sort through all the images to distinguish photos of snow leopards and their prey from photos which have neither. "Manual image sorting is a time-consuming and costly process," Sengupta says. "In fact, it takes around 300 hours per camera survey. In addition, data collection practices have changed over the years."
We have worked to help automate the Trust's snow leopard detection pipeline with Microsoft Machine Learning for Apache Spark (MMLSpark). This includes both classifying snow leopard images, as well as extracting detected leopards to identify and match to a large database of known leopard individuals.
Step 1: Gathering Data
Gathering data is often the hardest part of the machine learning workflow. Without a large, high-quality dataset, a project is likely never to get off the ground. However, for many tasks, creating a dataset is incredibly difficult, time consuming, or downright impossible. We were fortunate to work with the Snow Leopard Trust who have already gathered 10 years of camera trap data and have meticulously labelled thousands of images. However, the trust cannot release this data to the public, due to risks from poachers who use photo metadata to pinpoint leopards in the wild. As a result, if you are looking to create your own Snow Leopard analysis, you need to start from scratch.

Figure 2: Examples of camera trap images from the Snow Leopard Trust's dataset.
Announcing: Bing on Spark
Confronted with the challenge of creating a snow leopard dataset from scratch, it's hard to know where to start. Amazingly, we don't need to go to Kyrgyzstan and set up a network of motion sensitive cameras. We already have access to one of the richest sources of human knowledge on the planet – the internet. The tools that we have created over the past two decades that index the internet's content not only help humans learn about the world but can also help the algorithms we create do the same.
Today we are releasing an integration between the Azure Cognitive Services and Apache Spark that enables querying Bing and many other intelligent services at massive scales. This integration is part of the Microsoft ML for Apache Spark (MMLSpark) open source project. The Cognitive Services on Spark make it easy to integrate intelligence into your existing Spark and SQL workflows on any cluster using Python, Scala, Java, or R. Under the hood, each Cognitive Service on Spark leverages Spark's massive parallelism to send streams of requests up to the cloud. In addition, the integration between SparkML and the Cognitive Services makes it easy to compose services with other models from the SparkML, CNTK, TensorFlow, and LightGBM ecosystems.
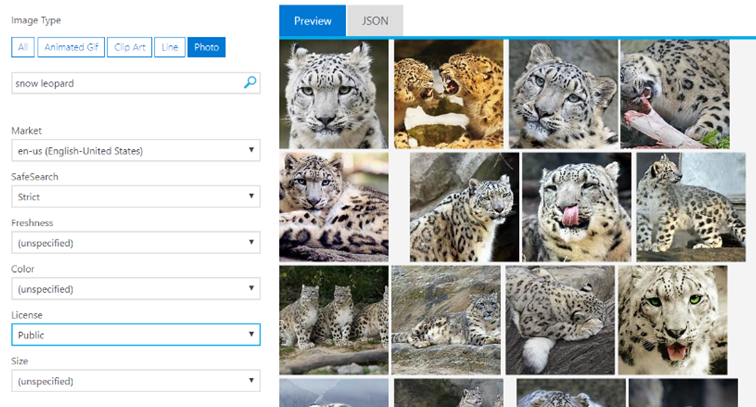
Figure 3: Results for Bing snow leopard image search.
We can use Bing on Spark to quickly create our own machine learning datasets featuring anything we can find online. To create a custom snow leopard dataset takes only two distributed queries. The first query creates the "positive class" by pulling the first 80 pages of the "snow leopard" image results. The second query creates the "negative class" to compare our leopards against. We can perform this search in two different ways, and we plan to explore them both in upcoming posts. Our first option is to search for images that would look like the kinds of images we will be getting out in the wild, such as empty mountainsides, mountain goats, foxes, grass, etc. Our second option draws inspiration from Noise Contrastive Estimation, a mathematical technique used frequently in the Word Embedding literature. The basic idea behind noise contrastive estimation is to classify our snow leopards against a large and diverse dataset of random images. Our algorithm should not only be able to tell a snow leopard from an empty photo, but from a wide variety of other objects in the visual world. Unfortunately, Bing Images does not have a random image API we could use to make this dataset. Instead, we can use random queries as a surrogate for random sampling from Bing. Generating thousands of random queries is surprisingly easy with one of the multitude of online random word generators. Once we generate our words, we just need to load them into a distributed Spark DataFrame and pass them to Bing Image Search on Spark to grab the first 10 images for each random query.
With these two datasets in hand, we can add labels, stitch them together, dedupe, and download the image bytes to the cluster. SparkSQL parallelizes this process and can speed up the download by orders of magnitude. It only takes a few seconds on a large Azure Databricks cluster to pull thousands of images from around the world. Additionally, once the images are downloaded, we can easily preprocess and manipulate them with tools like OpenCV on Spark.
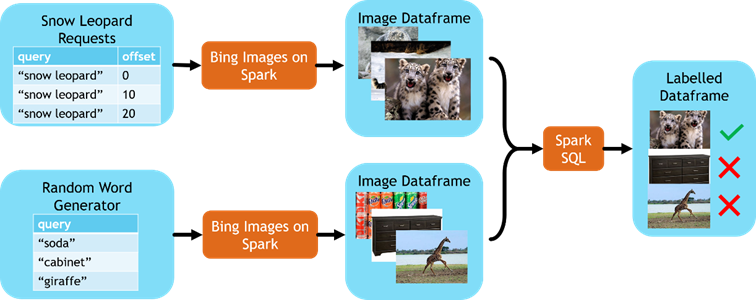
Figure 4: Diagram showing how to create a labelled dataset for snow leopard classification using Bing on Spark.
Step 2: Creating a Deep Learning Classifier
Now that we have a labelled dataset, we can begin thinking about our model. Convolutional neural networks (CNNs) are today's state-of-the-art statistical models for image analysis. They appear in everything from driverless cars, facial recognition systems, and image search engines. To build our deep convolution network, we used MMLSpark, which provides easy-to-use distributed deep learning with the Microsoft Cognitive Toolkit on Spark.
MMLSpark makes it especially easy to perform distributed transfer learning, a deep learning technique that mirrors how humans learn new tasks. When we learn something new, like classifying snow leopards, we don't start by re-wiring our entire brain. Instead, we rely on a wealth of prior knowledge gained over our lifetimes. We only need a few examples, and we quickly become high accuracy snow leopard detectors. Amazingly transfer learning creates networks with similar behavior. We begin by using a Deep Residual Network that has been trained on millions of generic images. Next, we cut off a few layers of this network and replace them with a SparkML model, like Logistic Regression, to learn a final mapping from deep features to snow leopard probabilities. As a result, our model leverages its previous knowledge in the form of intelligent features and can adapt itself to the task at hand with the final SparkML Model. Figure 5 shows a schematic of this architecture.
With MMLSpark, it's also easy to add improvements to this basic architecture like dataset augmentation, class balancing, quantile regression with LightGBM on Spark, and ensembling. To learn more, explore our journal paper on this work, or try the example on our website.
It's important to remember that our algorithm can learn from data sourced entirely from Bing. It did not need hand labeled data, and this method is applicable to almost any domain where an image search engine can find your images of interest.
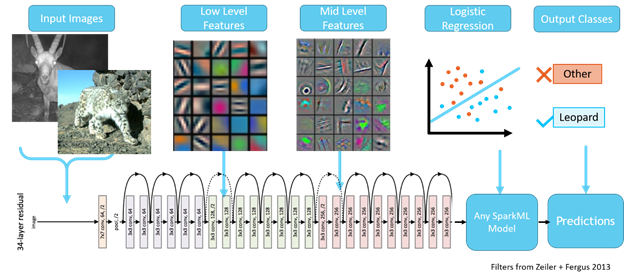
Figure 5: A diagram of transfer learning with ResNet50 on Spark.
Step 3: Creating an Object Detection Dataset with Distributed Model Interpretability
At this point, we have shown how to create a deep image classification system that leverages Bing to eliminate the need for labelled data. Classification systems are incredibly useful for counting the number of sightings. However, classifiers tell us nothing about where the leopard is in the image, they only return a probability that a leopard is in an image. What might seem like a subtle distinction, can really make a difference in an end to end application. For example, knowing where the leopard is can help humans quickly determine whether the label is correct. It can also be helpful for situations where there might be more than one leopard in the frame. Most importantly for this work, to understand how many individual leopards remain in the wild, we need to cross match individual leopards across several cameras and locations. The first step in this process is cropping the leopard photos so that we can use wildlife matching algorithms like HotSpotter.
Ordinarily, we would need labels to train an object detector, aka painstakingly drawn bounding boxes around each leopard image. We could then train an object detection network learn to reproduce these labels. Unfortunately, the images we pull from Bing have no such bounding boxes attached to them, making this task seem impossible.
At this point we are so close, yet so far. We can create a system to determine whether a leopard is in the photo, but not where the leopard is. Thankfully, our bag of machine learning tricks is not yet empty. It would be preposterous if our deep network could not locate the leopard. How could anything reliably know that there is a snow leopard in the photo without seeing it directly? Sure, the algorithm could focus on aggregate image statistics like the background or the lighting to make an educated guess, but a good leopard detector should know a leopard when it sees it. If our model understands and uses this information, the question is "How do we peer into our model's mind to extract this information?".
Thankfully, Marco Tulio Ribeiro and a team of researchers at the University of Washington have created an method called LIME (Local Interpretable Model Agnostic Explanations), for explaining the classifications of any image classifier. This method allows us to ask our classifier a series of questions, that when studied in aggregate, will tell us where the classifier is looking. What's most exciting about this method, is that it makes no assumptions about the kind of model under investigation. You can explain your own deep network, a proprietary model like those found in the Microsoft cognitive services, or even a (very patient) human classifier. This makes it widely applicable not just across models, but also across domains.

Figure 6: Diagram showing the process for interpreting an image classifier.
Figure 6 shows a visual representation of the LIME process. First, we will take our original image, and break it into "interpretable components" called "superpixels". More specifically, superpixels are clusters of pixels that groups pixels that have a similar color and location together. We then take our original image and randomly perturb it by "turning off" random superpixels. This results in thousands of new images which have parts of the leopard obscured. We can then feed these perturbed images through our deep network to see how our perturbations affect our classification probabilities. These fluctuations in model probabilities help point us to the superpixels of the image that are most important for the classification. More formally, we can fit a linear model to a new dataset where the inputs are binary vectors of superpixel on/off states, and the targets are the probabilities that the deep network outputs for each perturbed image. The learned linear model weights then show us which superpixels are important to our classifier. To extract an explanation, we just need to look at the most important superpixels. In our analysis, we use those that are in the top ~80% of superpixel importances.
LIME gives us a way to peer into our model and determine the exact pixels it is leveraging to make its predictions. For our leopard classifier, these pixels often directly highlight the leopard in the frame. This not only gives us confidence in our model, but also providing us with a way to generate richer labels. LIME allows us to refine our classifications into bounding boxes for object detection by drawing rectangles around the important superpixels. From our experiments, the results were strikingly close to what a human would draw around the leopard.

Figure 7: LIME pixels tracking a leopard as it moves through the mountains
Announcing: LIME on Spark
LIME has amazing potential to help users understand their models and even automatically create object detection datasets. However, LIME's major drawback is its steep computational cost. To create an interpretation for just one image, we need to sample thousands of perturbed images, pass them all through our network, and then train a linear model on the results. If it takes 1 hour to evaluate your model on a dataset, then it could take at least 50 days of computation to convert these predictions to interpretations. To help make this process feasible for large datasets, we are releasing a distributed implementation of LIME as part of MMLSpark. This will enable users to quickly interpret any SparkML image classifier, including those backed by deep network frameworks like CNTK or TensorFlow. This helps make complex workloads like the one described, possible in only a few lines of MMLSpark code. If you would like to try the code, please see our example notebook for LIME on Spark.


Figure 8: Left: Outline of most important LIME superpixels. Right: example of human-labeled bounding box (blue) versus the LIME output bounding box (yellow)
Step 4: Transferring LIME's Knowledge into a Deep Object Detector
By combining our deep classifier with LIME, we have created a dataset of leopard bounding boxes. Furthermore, we accomplished this without having to manually classify or labelling any images with bounding boxes. Bing Images, Transfer Learning, and LIME have done all the hard work for us. We can now use this labelled dataset to learn a dedicated deep object detector capable of approximating LIME's outputs at a 1000x speedup. Finally, we can deploy this fast object detector as a web service, phone app, or real-time streaming application for the Snow Leopard Trust to use.
To build our Object Detector, we used the TensorFlow Object Detection API. We again used deep transfer learning to fine-tune a pre-trained Faster-RCNN object detector. This detector was pre-trained on the Microsoft Common Objects in Context (COCO) object detection dataset. Just like transfer learning for deep image classifiers, working with an already intelligent object detector dramatically improves performance compared to learning from scratch. In our analysis we optimized for accuracy, so we decided to use a Faster R-CNN network with an Inception Resnet v2. Figure 9 shows speeds and performances of several network architectures, FRCNN + Inception Resnet V2 models tend to cluster towards the high accuracy side of the plot.
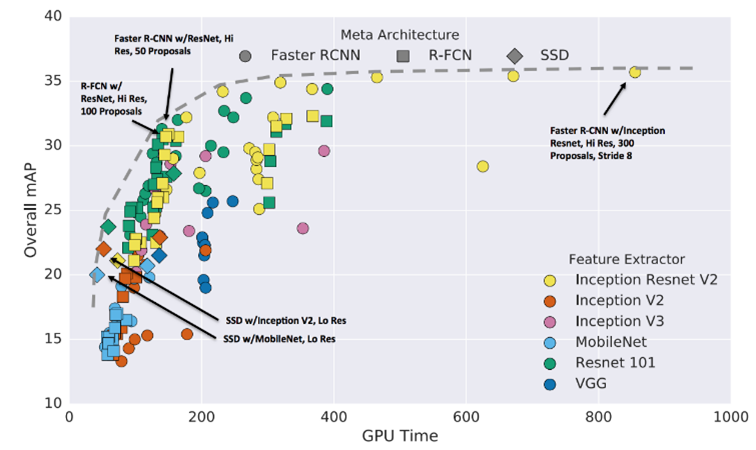
Figure 9: Speed/accuracy tradeoffs for modern convolutional object detectors. (Source: Google Research.)
Results
We found that Faster R-CNN was able to reliably reproduce LIME's outputs in a fraction of the time. Figure 10 shows several standard images from the Snow Leopard Trust's dataset. On these images, Faster R-CNN's outputs directly capture the leopard in the frame and match near perfectly with human curated labels.

Figure 10: A comparison of human labeled images (left) and the outputs of the final trained Faster-RCNN on LIME predictions (right).

Figure 11: A comparison of difficult human labeled images (left) and the outputs of the final trained Faster-RCNN on LIME predictions (right).
However, some images still pose challenges to this method. In Figure 11, we examine several mistakes made by the object detector. In the top image, there are two discernable leopards in the frame, however Faster R-CNN is only able to detect the larger leopard. This is due to the method used to convert LIME outputs to bounding boxes. More specifically, we use a simple method that bounds all selected superpixels with a single rectangle. As a result, our bounding box dataset has at most one box per image. To refine this procedure, one could potentially cluster the superpixels to identify if there are more than one object in the frame, then draw the bounding boxes. Furthermore, some leopards are difficult to spot due to their camouflage and they slip by the detector. Part of this affect might be due to anthropic bias in Bing Search. Namely, Bing Image Search returns only the clearest pictures of leopards and these photos are much easier than your average camera trap photo. To mitigate this effect, one could engage in rounds of hard negative mining, augment the Bing data with hard to see leopards, and upweight those examples which show difficult to spot leopards.
Step 5: Deployment as a Web Service
The final stage in our project is to deploy our trained object detector so that the Snow Leopard trust can get model predictions from anywhere in the world.
Announcing: Sub-millisecond Latency with Spark Serving
Today we are excited to announce a new platform for deploying Spark Computations as distributed web services. This framework, called Spark Serving, dramatically simplifies the serving process in Python, Scala, Java and R. It supplies ultra-low latency services backed by a distributed and fault-tolerant Spark Cluster. Under the hood, Spark Serving takes care of spinning up and managing web services on each node of your Spark cluster. As part of the release of MMLSpark v0.14, Spark Serving saw a 100-fold latency reduction and can now handle responses within a single millisecond.
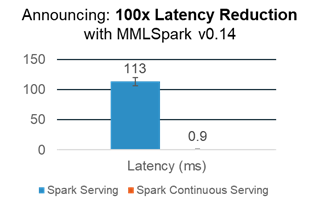
Figure 12: Spark Serving latency comparison.
We can use this framework to take our deep object detector trained with Horovod on Spark, and deploy it with only a few lines of code. To try deploying a SparkML model as a web service for yourself, please see our notebook example.
Future Work
The next step of this project is to use this leopard detector to create a global database of individual snow leopards and their sightings across locations. We plan to use a tool called HotSpotter to automatically identify individual leopards using their uniquely patterned spotted fur. With this information, researchers at the Snow Leopard Trust can get a much better sense of leopard behavior, habitat, and movement. Furthermore, identifying individual leopards helps researcher understand population numbers, which are critical for justifying Snow Leopard protections.
Conclusion
Through this project we have seen how new open source computing tools such as the Cognitive Services on Spark, Deep Transfer Learning, Distributed Model Interpretability, and the TensorFlow Object Detection API can work together to pull an domain specific object detector directly from Bing. We have also released three new software suites: The Cognitive Services on Spark, Distributed Model Interpretability, and Spark Serving, to make this analysis simple and performant on Spark Clusters like Azure Databricks.
To recap, our analysis consisted of the following main steps:
- We gathered a classification dataset using Bing on Spark.
- We trained a deep classifier using transfer learning with CNTK on Spark.
- We Interpreted this deep classifier using LIME on Spark to get regions of interest and bounding boxes.
- We learned a deep object detector using transfer learning that recreates LIME's outputs at a fraction of the cost.
- We deployed the model as a distributed web service with Spark Serving.
Here is a graphical representation of this analysis:
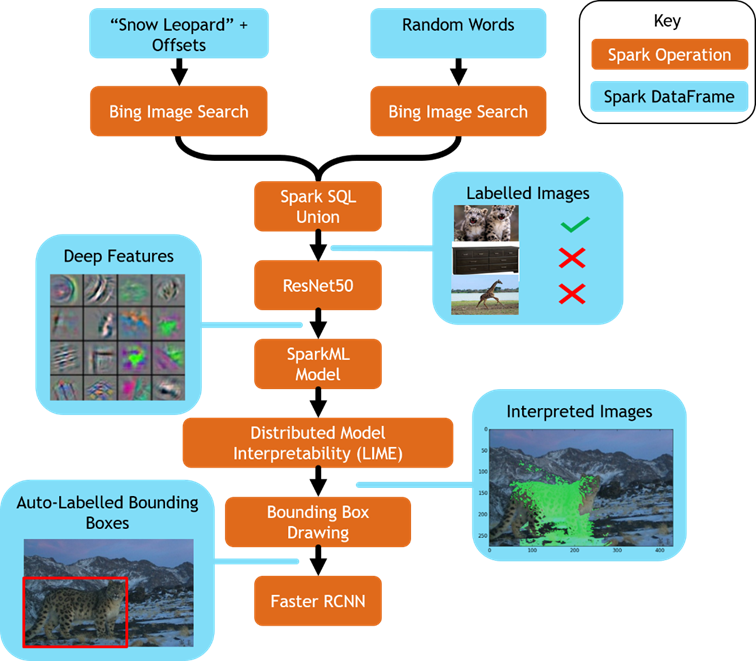
Figure 13: Overview of the full architecture described in this blog post.
Using Microsoft ML for Apache Spark, users can easily follow in our footsteps and repeat this analysis with their own custom data or Bing queries. We have published this work in the open source and invite others to try it for themselves, give feedback, and help us advance the field of distributed unsupervised learning.
We have applied this method to help protect and monitor the endangered snow leopard population, but we made no assumptions throughout this blog on the type of data used. Within a few hours we were able to modify this workflow to create a gas station fire detection network for Shell Energy with similar success.
Mark Hamilton, for the MMLSpark Team
Resources:
- Web: https://aka.ms/spark
- Github: https://aka.ms/mmlspark
- Email: mmlspark-support@microsoft.com